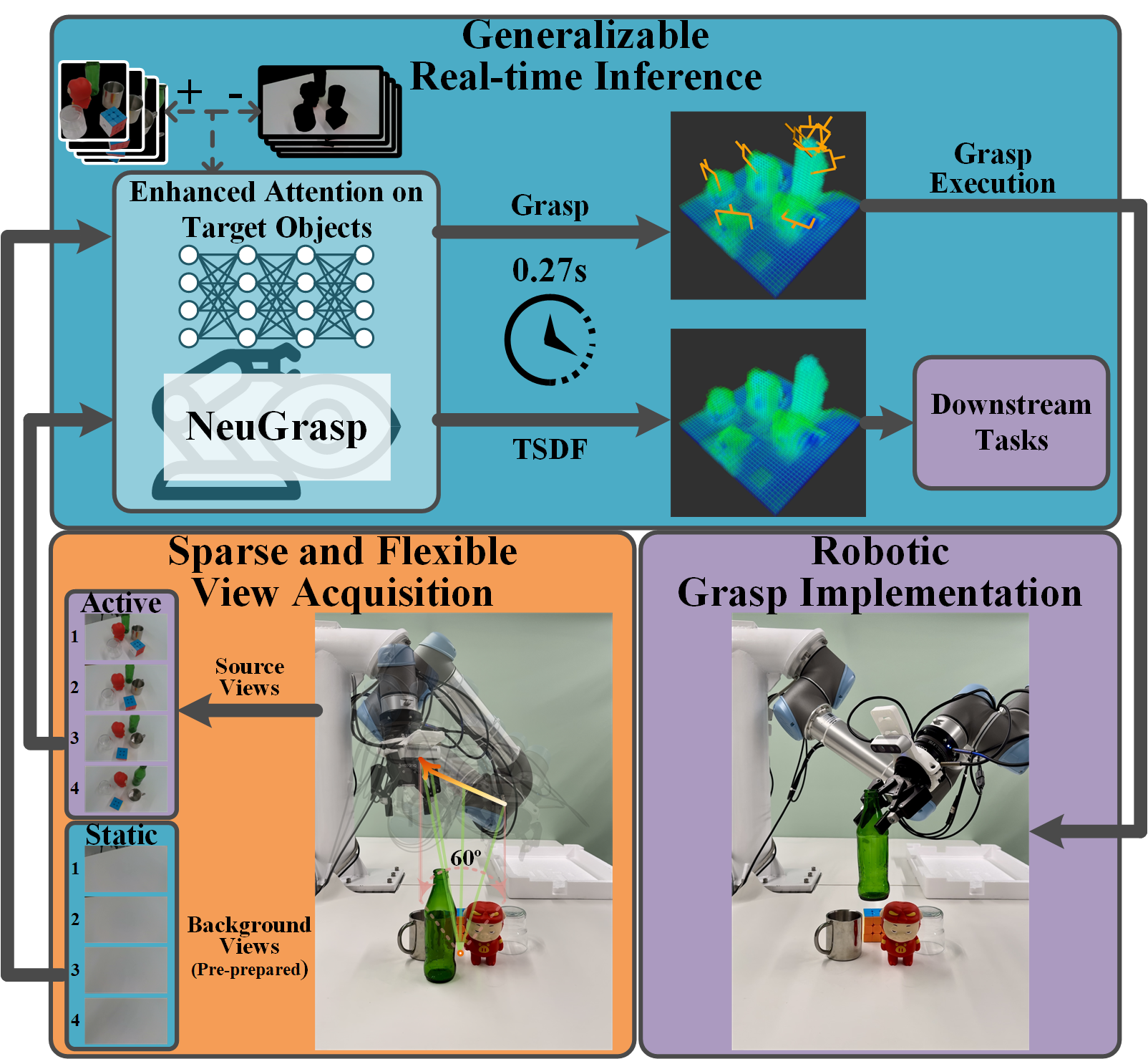
Robotic grasping in scenes with transparent and specular objects presents great challenges for methods relying on accurate depth information. In this paper, we introduce NeuGrasp, a neural surface reconstruction method that leverages background priors for material-agnostic grasp detection. NeuGrasp integrates transformers and global prior volumes to aggregate multi-view features with spatial encoding, enabling robust surface reconstruction in narrow and sparse viewing conditions. By focusing on foreground objects through residual feature enhancement and refining spatial perception with an occupancy-prior volume, NeuGrasp excels in handling objects with transparent and specular surfaces. Extensive experiments in both simulated and real-world scenarios show that NeuGrasp outperforms state-of-the-art methods in grasping while maintaining comparable reconstruction quality.